RelMobNet: End-to-end relative camera pose estimation using a robust two-stage training
 RelMobNet
RelMobNet
Abstract
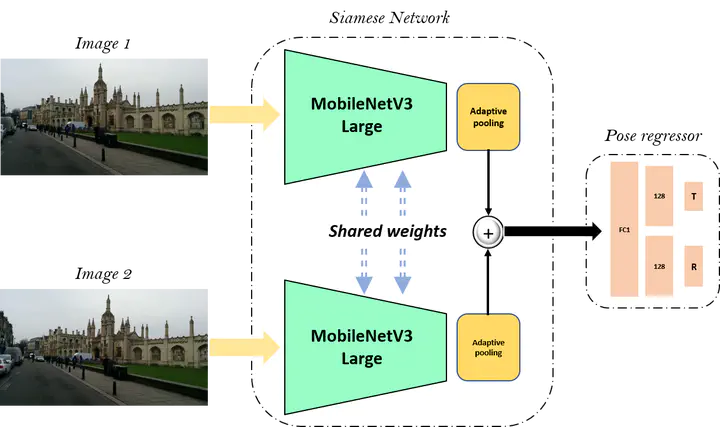
Relative camera pose estimation plays a pivotal role in dealing with 3D reconstruction and visual localization. To address this, we propose a Siamese network based on MobileNetV3-Large for an end-to-end relative camera pose regression independent of camera parameters. The proposed network uses pair of images taken at different locations in the same scene to estimate the 3D translation vector and rotation vector in unit quaternion. To increase the generality of the model, rather than training it for a single scene, data for four scenes are combined to train a single universal model to estimate the relative pose. Further for independency of hyperparameter weighing between translation and rotation loss is not used. Instead we use the novel two-stage training procedure to learn the balance implicitly with faster convergence. We compare the results obtained with the Cambridge Landmarks dataset, comprising of different scenes, with existing CNN-based regression methods as baselines, e.g., RPNet and RCPNet. The findings indicate that, when compared to RCPNet, proposed model improves the estimation of the translation vector by a percentage change of 16.11%, 28.88%, 52.27% on the Kings College, Old Hospital, St Marys Church scenes from Cambridge Landmarks dataset, respectively.
Praveen Kumar Rajendran
M.S Candiate
My research interests include deep learning, 3D computer vision and autonomous driving.